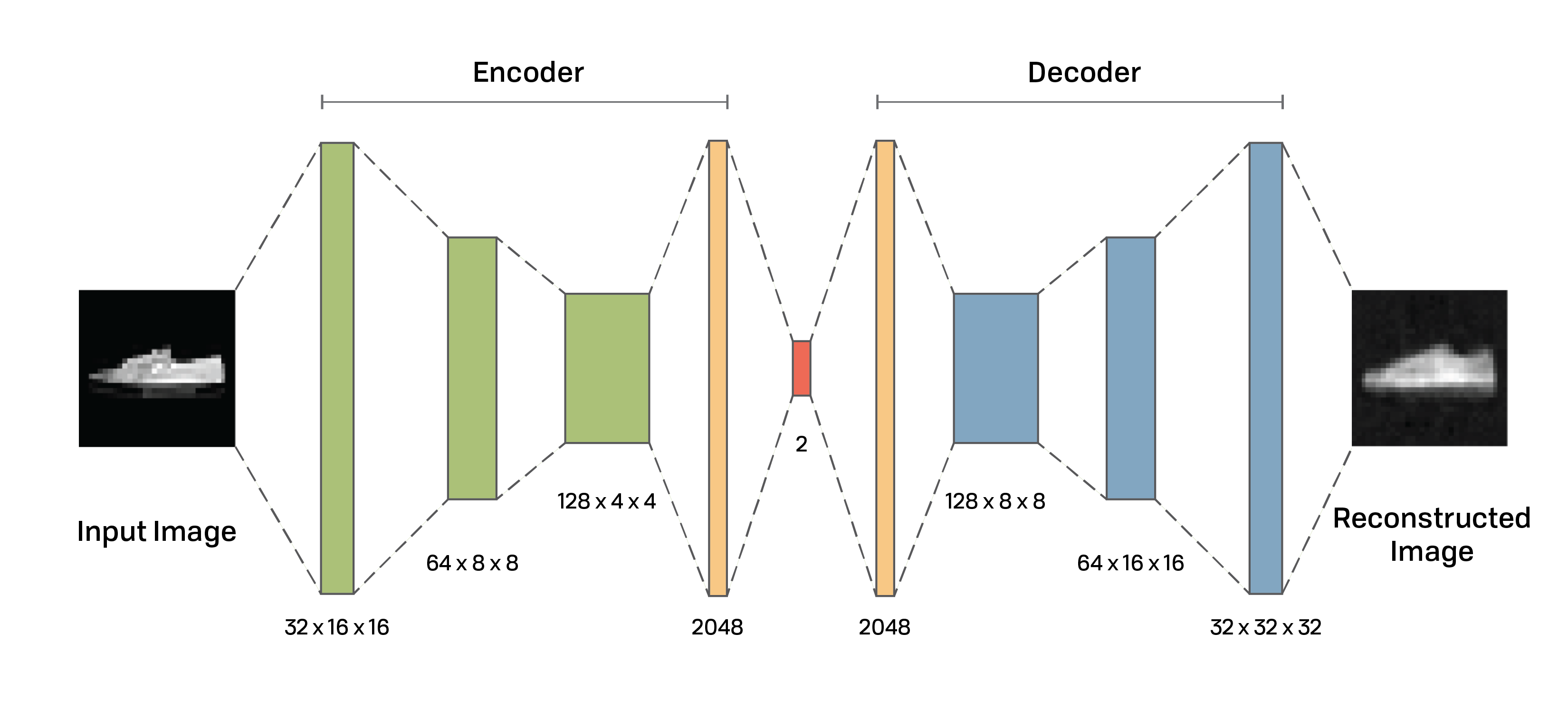
OpenAI Research Paper Identifies LLM Hallucinations as Guessing Errors, Proposes Eval Reform
A new OpenAI research paper, "From Pretraining to Post-Training: Why Language Models Hallucinate and How Evaluation Methods Reinforce the Problem," posits that large language model (LLM) hallucinations stem primarily from guessing errors, which are exacerbated by current training and evaluation paradigms. The paper argues that standard benchmarks and evaluations frequently reward confident guessing over honest uncertainty, causing LLMs to prioritize generating a "right" answer rather than admitting "I don't know." These statistically predictable errors arise from cross-entropy optimization during pretraining (especially on rare "singleton" facts) and binary-graded post-training benchmarks that penalize abstention, effectively incentivizing models to "bluff." The proposed solution involves a fundamental shift in mainstream evaluations, introducing explicit confidence thresholds and partial credit for abstention, which could realign incentives, foster behavioral calibration, and reduce overconfident falsehoods. This insight suggests a path towards more reliable and calibrated LLMs, with OpenAI sharing these findings via its social media channels.




 +5
+5